How a NAS System Uses Predictive Namespace Indexing to Accelerate File Lookup in Billion-File Environments?
- Mary J. Williams
- Apr 23
- 4 min read

Managing unstructured data at a massive scale requires fundamental shifts in storage architecture. When an organization scales its storage infrastructure to accommodate billions of files, traditional directory traversal methods become severely bottlenecked. Administrators frequently experience significant latency during routine file lookups, metadata queries, and permission audits. The core issue lies in how a standard file system structures and retrieves data across sprawling directory trees.
To overcome these latency issues, a modern NAS system utilizes predictive namespace indexing. This advanced computational approach pre-calculates and flattens directory structures into highly optimized, searchable indexes. Instead of executing serial directory reads that consume extensive disk I/O and CPU cycles, the storage controller queries a memory-resident database. This results in file lookup times dropping from minutes to milliseconds, regardless of the directory depth or total file count.
Deploying an enterprise NAS equipped with predictive indexing completely transforms data management for high-performance computing, media rendering, and large-scale analytical workloads. Organizations can locate specific datasets instantaneously, accelerating downstream processing. Furthermore, this method integrates seamlessly with comprehensive NAS security protocols, ensuring that rapid access does not compromise data governance or access controls.
This post examines the mechanics of predictive namespace indexing, detailing how a high-capacity NAS system leverages this technology to accelerate data retrieval while maintaining strict enterprise storage standards.
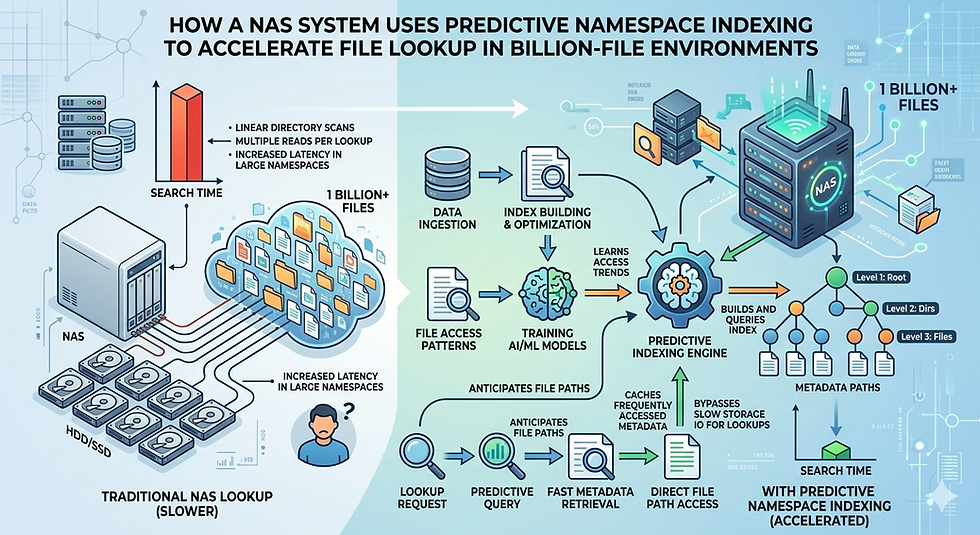
The Bottleneck of Traditional File Systems
Legacy file systems rely on a hierarchical tree structure. When an application requests a file, the storage controller must navigate from the root directory down through every intermediate subdirectory. In a billion-file environment, this process, known as tree-walking, generates a massive volume of metadata read requests.
Because metadata is often distributed across multiple storage drives, tree-walking forces the NAS system to execute numerous random read operations. This mechanical reality creates latency. Even with solid-state drives, the sheer volume of serial operations overloads the storage controller. As the directory grows, the time required to complete a single file lookup increases exponentially.
An enterprise NAS cannot afford this degradation in performance. High-performance workloads require deterministic, predictable access times. When traditional tree-walking fails to deliver, the entire data pipeline stalls, severely impacting organizational productivity and computational efficiency.
Mechanics of Predictive Namespace Indexing
Predictive namespace indexing resolves tree-walking latency by decoupling the logical directory structure from the physical metadata retrieval process. Instead of traversing the tree dynamically during a read request, the NAS system continuously maps the file system namespace into a highly structured, memory-resident index.
This index functions similarly to a relational database. It stores the exact physical location of every file, alongside critical metadata such as creation dates, file sizes, and ownership details. When a user or application issues a file lookup request, the enterprise NAS bypasses the hierarchical tree entirely. The storage controller queries the index directly, retrieving the exact file location in a single operation.
To keep the index accurate, the system utilizes predictive algorithms. As files are written, modified, or deleted, the index updates asynchronously. The predictive component anticipates access patterns, caching the most frequently accessed namespace segments in the highest-performing memory tiers. This ensures that the NAS system always delivers optimal performance for hot datasets, minimizing disk I/O and preserving computational resources for actual data transfer.
Maintaining Strict NAS Security at Scale
Accelerating file lookups introduces potential challenges for data governance. If an index grants instantaneous visibility into billions of files, the storage architecture must enforce access controls with equal speed. A robust enterprise NAS integrates access control lists (ACLs) and permission metadata directly into the predictive index.
By unifying indexing and permissions, NAS security becomes proactive rather than reactive. When a query hits the index, the system evaluates the user's security credentials against the indexed permission sets before confirming the file's existence. If a user lacks the appropriate clearance, the system filters those files from the search results instantly.
This architecture prevents unauthorized directory browsing and strengthens overall NAS security. Traditional systems often struggle to audit permissions across billions of files, leaving organizations vulnerable to compliance violations. Because the predictive index maintains a real-time ledger of all file permissions, administrators can execute instant security audits. They can identify exposed data, verify access logs, and enforce strict NAS security policies across the entire storage cluster without degrading user performance.
Architectural Advantages for the Enterprise
Implementing predictive namespace indexing provides cascading benefits across the storage infrastructure. Beyond accelerating file lookups, it drastically reduces the computational overhead on the storage controllers. Because the system no longer executes millions of random metadata reads, those CPU and RAM resources are freed up to handle raw data throughput.
This efficiency is a defining characteristic of a modern enterprise NAS. Organizations can serve more concurrent users and support more demanding applications without constantly upgrading their hardware. The index also facilitates rapid data management tasks. Operations that typically take days in a billion-file environment—such as storage tiering, data migration, and backup cataloging—can be completed in hours or minutes.
Furthermore, this approach enhances data visibility. Administrators can query the index to generate real-time reports on storage consumption, identifying orphaned data or capacity bottlenecks. By leveraging these insights, organizations can optimize their storage investments, moving cold data to cheaper archival tiers while reserving high-performance drives for active workloads.
Optimizing High-Scale Storage Infrastructures
Managing billions of files requires abandoning legacy hierarchical traversal in favor of database-driven metadata management. Predictive namespace indexing provides the mathematical framework necessary to locate data instantaneously, regardless of the total storage volume.
By deploying a modern NAS system equipped with this technology, organizations eliminate latency bottlenecks and maximize their infrastructure investments. They achieve the deterministic performance required for advanced computing while enforcing rigorous NAS security protocols across every file.
For IT administrators tasked with scaling their data centers, evaluating an enterprise NAS based on its metadata handling capabilities is critical. Prioritize systems that offer integrated, real-time namespace indexing. By doing so, you ensure that your storage infrastructure remains a high-speed asset, rather than a computational bottleneck, as your data continues to grow.


Comments