How Scale-Out NAS Evolved from Basic Clusters to Intelligent Distributed File Systems for High-Performance Workloads?
- Mary J. Williams
- Mar 18
- 4 min read

Data generation is expanding at an unprecedented rate, forcing enterprises to rethink how they store, manage, and process massive datasets. High-performance workloads—such as genomic sequencing, financial modeling, and artificial intelligence training—require storage solutions that can deliver both massive capacity and high throughput simultaneously.
Historically, organizations relied on a traditional NAS System to handle file-level data. However, as data demands grew, these legacy systems struggled to maintain performance. This operational bottleneck drove the industry to develop scale-out NAS, shifting the paradigm from rigid hardware constraints to flexible, clustered environments.
This post examines the architectural progression of network-attached storage. By understanding the transition from basic storage clusters to intelligent distributed file systems, IT architects can better design storage infrastructures capable of supporting modern, high-performance computing requirements.

The Limitations of Traditional Scale-Up Storage
To understand the necessity of modern distributed file systems, it is vital to examine the constraints of early storage architectures. A legacy NAS system typically utilizes a scale-up approach. In contrast, scale-out NAS architectures distribute computing power, memory, and network bandwidth across multiple nodes. In the scale-up model, the storage controller has a fixed amount of computing power, memory, and network bandwidth, creating limitations as workloads grow.
Processing and Bandwidth Bottlenecks
When an enterprise needs more storage capacity in a scale-up architecture, administrators add disk shelves to the existing controller. While this increases the total terabytes available, the processing power remains static. Eventually, the single controller becomes overwhelmed by the increasing volume of read and write requests. This imbalance leads to severe latency issues, making the system unsuitable for data-intensive applications that require high IOPS (Input/Output Operations Per Second) and low latency.
The Transition to Basic Clustered Storage
Engineers developed scale-out NAS to solve the inherent performance limitations of a single-controller architecture. Instead of adding passive disk shelves to a single head unit, a scale-out architecture introduces independent nodes. Each node contains its own CPU, memory, network interfaces, and storage drives.
Aggregating Nodes for Linear Performance
By clustering these independent nodes together under a single namespace, the system pools the. By clustering these independent nodes together under a single namespace, the NAS system pools the resources. When administrators add a new node to a scale-out NAS cluster, they increase the total storage capacity while simultaneously adding compute and network bandwidth. This linear scaling model allows organizations to handle heavier workloads without hitting the processing ceiling of a single controller. Early clustered systems distributed files across the nodes, ensuring that no single hardware component became a critical bottleneck.
The Rise of Intelligent Distributed File Systems
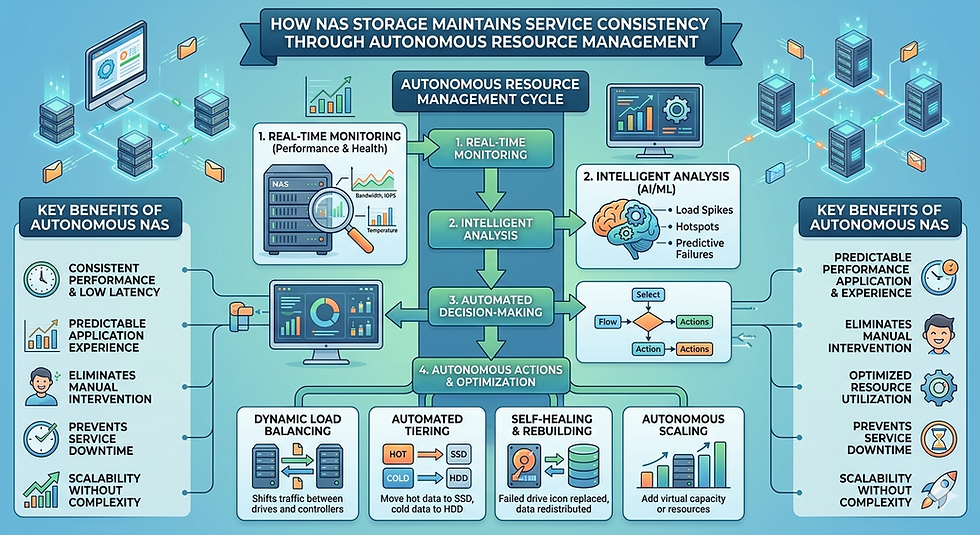
While basic clustered NAS solved the linear scaling problem, modern high-performance workloads require more than just aggregated hardware. They need intelligent data management. This requirement led to the development of intelligent distributed file systems.
Advanced Metadata Management
In a standard cluster, managing file metadata (information about where data physically resides) can cause significant latency if not handled correctly. Intelligent distributed file systems decouple metadata from the actual file data. By using dedicated metadata servers or highly optimized distributed algorithms, these systems can process millions of file operations per second. This separation allows the compute nodes to retrieve and write large datasets instantly, which is a strict requirement for machine learning and real-time analytics.
Automated Data Tiering and Machine Learning
Modern scale-out NAS also incorporates intelligent data tiering. Using machine learning algorithms, the system monitors data access patterns. It automatically moves "hot" (frequently accessed) data to high-performance NVMe solid-state drives, while seamlessly migrating "cold" (infrequently accessed) data to high-capacity, lower-cost spinning disks or object storage. This process happens in the background, entirely transparent to the end-user or application, optimizing both performance and storage costs.
Deploying Modern NAS in AWS Cloud
The evolution of storage architecture does not stop at the edge of the on-premises data center. Enterprises are increasingly migrating their high-performance workloads to the cloud to leverage elastic compute resources. Operating a NAS In AWS Cloud environments allows organizations to combine the robust file management of distributed file systems with the flexibility of cloud infrastructure.
Cloud-Native High-Performance Workloads
Implementing a scale-out NAS In AWS Cloud removes the need for hardware procurement and physical maintenance. Cloud-native NAS solutions provide a POSIX-compliant file system that integrates directly with AWS computing instances like Amazon EC2. This setup is highly advantageous for bursty workloads, such as video rendering or algorithmic trading, where an organization might need to spin up thousands of compute cores for a few hours. The scale-out file system dynamically expands to feed data to these instances at maximum throughput, then scales down when the workload completes, ensuring strict cost efficiency.
Future-Proofing Data Infrastructure
The trajectory of storage technology clearly favors decentralized, highly intelligent architectures. From the rigid limitations of a single-controller NAS System to the dynamic capabilities of modern distributed file systems, the industry has systematically eliminated performance bottlenecks.
As enterprises continue to deploy high-throughput applications, adopting a robust scale-out NAS architecture—whether deployed on-premises or integrated as a NAS In AWS Cloud—is no longer optional. It is a fundamental requirement. By implementing these advanced storage systems, IT leaders can ensure their infrastructure remains resilient, scalable, and fully capable of powering the next generation of data-driven innovation.


Comments