How Scale Out NAS Storage Coordinates Distributed Utilization Awareness Without Service Drift?
- Mary J. Williams
- May 13
- 4 min read

Managing data across distributed architectures requires precision and systemic cohesion. As enterprise environments expand, administrators face the complex challenge of distributing workloads without degrading performance. Central to solving this problem is the architecture of modern file storage systems. By implementing advanced protocols, systems can distribute utilization awareness seamlessly. This ensures that scaling capacity does not compromise operational stability.
Understanding the technical mechanics behind this coordination is essential for storage architects and IT administrators. When thousands of concurrent operations hit a distributed cluster, the system must balance the load, replicate data, and maintain metadata consistency. If nodes lose synchronization, the cluster experiences service drift. Service drift manifests as latency spikes, inconsistent data states, and eventual service degradation.
This article explains the internal mechanisms that allow scale out NAS storage to maintain distributed utilization awareness. By exploring node communication, metadata management, and load-balancing algorithms, you will gain a clear understanding of how these systems avoid service drift. Implementing these principles ensures highly available, consistent, and performant data infrastructure.
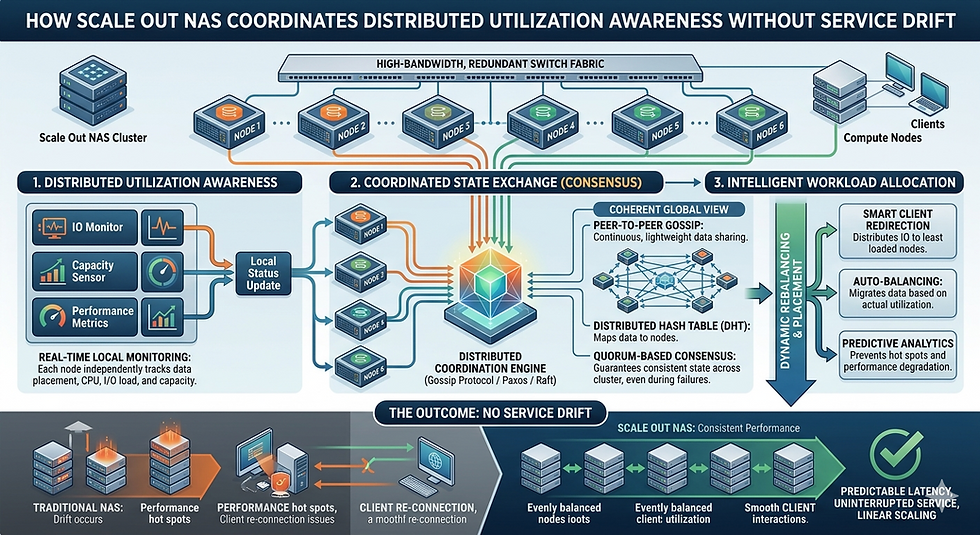
Architectural Foundations of Distributed File Systems
At the core of high-performance data management is network attached storage. Unlike traditional monolithic architectures that scale up by adding hardware to a single controller, modern architectures scale out. A scale out NAS storage cluster consists of multiple independent nodes. Each node contributes CPU, memory, and disk capacity to a single namespace.
This unified namespace requires tight coordination. When a client requests a file, the network attached storage system must route that request to the appropriate node. It must do so without requiring the client to know the underlying physical topology. This abstraction relies on an internal network, typically an ultra-low-latency backend switch fabric, which facilitates continuous state sharing among nodes.
The Mechanics of Distributed Utilization Awareness
To prevent resource bottlenecks, the cluster must possess real-time distributed utilization awareness. This means every node in the scale out NAS storage environment must understand the capacity and computing load of its peers.
Metadata Synchronization
Metadata operations often account for the majority of storage traffic. To coordinate utilization, the system uses distributed metadata management. Instead of relying on a centralized metadata server, which can become a single point of failure and a performance bottleneck, the network attached storage cluster distributes metadata across all nodes.
Nodes communicate via consensus protocols, such as Paxos or Raft. These protocols ensure that when a file is modified, the directory structure updates across the cluster synchronously. By continuously updating peer nodes on metadata changes, the scale out NAS storage system maintains a coherent state, ensuring that subsequent read or write requests access the most current version of the data.
Dynamic Load Balancing
Utilization awareness directly informs load balancing. As client connections enter the network attached storage cluster, an intelligent front-end routing mechanism assesses the current CPU and disk utilization of each node.
If Node A is processing a heavy batch of sequential writes, the system dynamically redirects incoming client connections to Node B or Node C. This dynamic redistribution prevents localized hardware exhaustion. Because the scale out NAS storage system shares a single file system namespace, the redirection occurs transparently to the end user or application.
Mitigating Service Drift in Clustered Environments
Service drift occurs when individual nodes in a distributed system fall out of sync with the cluster's global state. This can happen due to network latency, hardware degradation, or software bugs. Left unchecked, service drift leads to split-brain scenarios, corrupted files, and total cluster failure.
Quorum and Node Fencing
To prevent service drift, network attached storage utilizes quorum mechanisms. A quorum requires a strict majority of nodes to agree on the state of the system before committing a write operation. If a node loses connection to the backend cluster fabric, it can no longer participate in the quorum.
When a scale out NAS storage system detects an isolated node, it initiates node fencing. Fencing completely isolates the compromised node from the client network and the storage backend. This decisive action prevents the isolated node from serving stale data or corrupting the global file system, effectively eliminating service drift.
Continuous State Rebalancing
Preventing service drift also requires proactive maintenance of data distribution. As administrators add new nodes to the network attached storage cluster, the system must rebalance the data.
Scale out NAS storage systems handle this through background restriping processes. The cluster identifies over-utilized nodes and smoothly migrates data blocks to newly provisioned nodes. This process operates at a low priority to avoid interrupting active client I/O. By constantly adjusting the physical location of data blocks to match the available hardware, the cluster maintains optimal distributed utilization awareness.
Enhancing Resilience Through Predictive Analytics
Modern infrastructure increasingly relies on predictive analytics to maintain system cohesion. By analyzing telemetry data from individual drives, network interfaces, and CPU cores, the storage cluster can predict hardware failures before they cause service drift.
When the network attached storage system detects an impending drive failure, it proactively evacuates the data from the failing component. The scale out NAS storage architecture allows this evacuation to happen concurrently across multiple healthy nodes. This many-to-many rebuild process drastically reduces the vulnerability window compared to traditional RAID rebuilds.
Optimizing Storage Operations for the Future
Managing distributed architectures requires an uncompromising approach to systemic coordination. By leveraging dynamic load balancing, distributed metadata protocols, and strict quorum enforcement, modern file systems deliver seamless scalability. They effectively distribute workloads, mitigate localized bottlenecks, and maintain strict data consistency.
Understanding these underlying mechanisms empowers enterprise architects to design more resilient infrastructures. When a scale out NAS storage system effectively coordinates distributed utilization awareness, it eliminates the risk of service drift. This guarantees that as organizational data grows, the network attached storage infrastructure remains a stable, highly available foundation for critical enterprise operations.


Comments