How Scale-Out NAS Storage Optimizes Rebuild Traffic Without Impacting Client Workloads
- Mary J. Williams
- Mar 27
- 4 min read

Drive failures are an inevitable reality in enterprise data centers. When a storage drive fails, the system must immediately initiate a rebuild process to restore data redundancy and prevent potential data loss. This rebuild process requires significant computational and network resources. If poorly managed, the background traffic generated by data reconstruction can severely degrade the performance of active client workloads.
For organizations managing massive datasets, ensuring high availability and consistent performance during component failure is critical. Traditional storage architectures often struggle to balance the urgent need for data protection with the steady demand of application I/O. As capacities grow, the time required to rebuild high-density drives increases, extending the window of vulnerability and potential performance degradation.
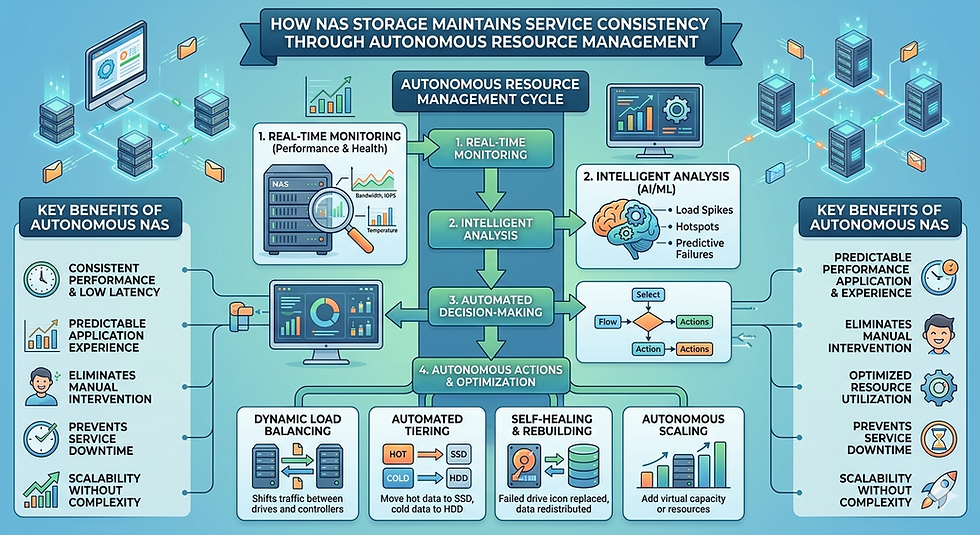
Scale out NAS storage addresses this operational challenge through distributed architectures and intelligent resource management. By distributing data and parity information across multiple nodes in a cluster, these modern systems can isolate and optimize rebuild traffic, ensuring that primary applications remain unaffected.

The Architecture of Scale-Out NAS Storage
To understand how rebuild traffic is optimized, it is necessary to examine the underlying architecture of scale out NAS storage. Unlike legacy monolithic systems, a scale-out architecture utilizes a clustered approach. Multiple storage nodes are interconnected to form a single, unified storage pool.
Distributed Data and Metadata
In a scale-out cluster, files are divided into blocks or objects and distributed across the available nodes. Metadata, which tracks file locations and attributes, is similarly distributed. When a client requests a file, the system retrieves the data concurrently from multiple nodes. This distributed approach prevents any single node from becoming a performance bottleneck during standard operations.
Parallel Processing Capabilities
Because data is spread across the entire cluster, the computational workload is also shared. Every node contributes CPU, memory, and network bandwidth to the overall system. This parallel processing capability is the foundational element that allows scale out NAS storage to handle intensive background tasks without monopolizing the resources required for client-facing operations.
Handling Failures: Legacy vs. Scale-Out NAS
The methodology for reconstructing lost data differs significantly depending on the storage architecture in place. Understanding this difference highlights the operational advantages of scale-out systems.
The Bottlenecks of Legacy NAS Storage
Traditional NAS storage typically relies on hardware RAID controllers to manage data redundancy. When a drive in a RAID group fails, the controller must read the surviving parity and data blocks from the remaining drives in that specific group to rebuild the lost information onto a hot spare. This localized rebuild process heavily taxes the specific disks in the RAID group and the dedicated controller. Consequently, any client application attempting to read or write to that same RAID group will experience high latency and reduced throughput.
Intelligent Rebuild Mechanics in Scale-Out Systems
Scale out NAS storage abandons localized RAID groups in favor of cluster-wide data protection schemes, such as erasure coding or distributed mirroring. When a drive or an entire node fails in a scale-out environment, the rebuild process is not confined to a small set of disks.
Instead, all surviving nodes in the cluster participate in the reconstruction. The system reads the necessary distributed data and parity fragments from dozens or hundreds of drives simultaneously. The newly reconstructed data is then written across the cluster's available free space. This many-to-many rebuild mechanism dramatically accelerates recovery times while distributing the hardware strain so thinly that individual client requests are rarely delayed.
Mechanisms for Isolating Rebuild Traffic
Beyond distributed parallel processing, enterprise-grade scale out NAS storage employs specific software mechanisms to actively manage and throttle rebuild traffic.
Quality of Service (QoS) Controls
Advanced NAS platforms integrate robust Quality of Service (QoS) frameworks. Storage administrators can define policies that guarantee minimum performance thresholds (IOPS or bandwidth) for mission-critical client workloads. When a rebuild is initiated, the QoS engine monitors cluster utilization in real-time. If the system detects that client I/O is approaching the defined performance limits, the QoS controller automatically throttles the rebuilt traffic.
Background Task Prioritization
System maintenance tasks, including data scrubbing, snapshot deletion, and drive rebuilds, are assigned distinct priority levels. Scale out NAS storage algorithms dynamically adjust the priority of the rebuild process based on the cluster's current load. During peak business hours, the rebuild might proceed at a conservative pace, utilizing only idle resources. During off-peak hours, the system can dynamically allocate maximum bandwidth to the rebuild process, completing the data reconstruction rapidly when client demand is low.
Maintaining Performance During Client Workloads
The ultimate goal of any enterprise storage system is to serve data to applications and users predictably. By leveraging a distributed architecture, parallel processing, and dynamic QoS controls, scale out NAS storage effectively decouples data protection processes from data delivery.
Clients continue to access their files via standard protocols (such as NFS or SMB) without experiencing the latency spikes traditionally associated with drive failures. The cluster absorbs the hardware fault, reconstructs the data across the backend network, and maintains the front-end performance SLAs required by the business.
Future-Proofing Your Storage Infrastructure
As storage densities continue to increase, the impact of drive failures will only become more pronounced. Organizations must adopt storage infrastructures capable of mitigating hardware faults seamlessly. Scale out NAS storage provides the resilient, distributed architecture necessary to protect massive datasets while ensuring continuous high performance. By intelligently managing rebuild traffic, these systems allow IT departments to maintain strict service level agreements, reduce operational risk, and keep critical business applications running smoothly regardless of underlying hardware disruptions.


Comments